Trong kỷ nguyên số, dữ liệu được ví như dầu mỏ.
Trong kỷ nguyên kỹ thuật số hiện nay, dữ liệu vẫn được ví như dầu mỏ. Không ít công ty tư nhân nhận ra rằng họ cần phải “đào” dữ liệu trong thế kỷ 21, nhất là dữ liệu cá nhân của khách hàng.
Có một số dạng dữ liệu mà ai cũng có thể tiếp cận, chẳng hạn như tên tuổi, địa chỉ, email, số điện thoại… Nhưng cũng có những “mỏ dầu” thượng hạng mà chỉ những công ty như Google mới đủ khả năng khai thác: dữ liệu di truyền chứa bộ gen hoàn chỉnh của chúng ta.
Nằm trong xu hướng cá nhân hóa người dùng, Google đang khai thác những dữ liệu được coi là định nghĩa lên mỗi người. Một mặt, nó có rất nhiều lợi ích, nhưng hoạt động này cũng gây ra rất nhiều tranh cãi.

Không chỉ tuổi tác và số điện thoại, Google bây giờ còn muốn biết cả bộ gen của bạn
Thu thập dữ liệu về trình tự gen trong dân số có thể mở ra nhiều tiềm năng rất lớn. Gen nắm giữ chìa khóa giúp chúng ta nâng cao hiểu biết về hàng loạt các căn bệnh bao gồm cả ung thư. Dĩ nhiên, mỗi hiểu biết về bản chất của bệnh tật đều là một bước tiến đến việc tìm cách chữa trị nó.
Eric Schmidtm, chủ tịch công ty mẹ Alphabet của Google, cho biết các thuật toán máy tính đang ngày càng được làm tốt hơn. Chúng ta cũng sẽ làm tốt hơn tương tự, trên khía cạnh nhận diện và cá nhân hóa con người với dữ liệu.
Trong tương lai, điều này sẽ cho phép mọi người đặt những câu hỏi “bói toán” với Google dạng như: “Tôi nên làm gì vào ngày mai?”, hoặc “Nghề nghiệp gì phù hợp với tôi trong tương lai?”.
Trên đường đi tới đích cuối cùng là cá nhân hóa mọi người dùng, Google đang sử dụng các thuật toán học máy để theo dõi hoạt động của chúng ta trên internet. Bạn có thể nhận ra các quảng cáo Google hiện ra rất sát với sở thích hoặc những gì bạn đang tìm kiếm.
Tất nhiên, Google không hề muốn dừng lại ở đó. Trong tương lai, họ còn có cả ý định phân tích dữ liệu y tế và di truyền của người dùng, nhằm đưa ra các dự đoán về sức khỏe, hoặc nói cho mỗi người biết họ nên làm gì với cuộc sống của mình.
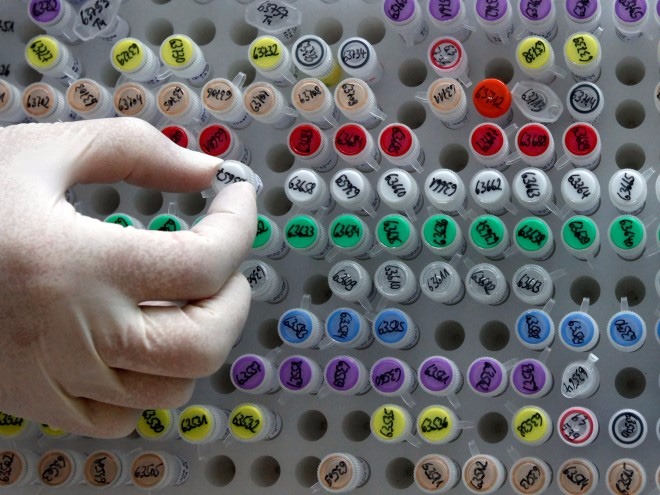
Vật chất di truyền được lưu trữ bên trong một phòng thí nghiệm tại Munich
Chính phủ Anh hiện đang có một dự án mang tên 100.000 Genomes Projects. Đúng như cái tên của nó, dự án này đặt mục tiêu thu thập trình tự gen hoàn chỉnh của 100.000 người. Và nếu nói rằng trình tự gen là thứ lột tả tất cả những gì thuộc về con người họ, ít nhất 100.000 bản thể trần trụi sẽ được số hóa và lưu trữ để sử dụng.
Năm 2014, Google mua lại DeepMind, một công ty trí tuệ nhân tạo của Anh. Họ đã đàm phán để DeepMind có thể tham gia theo dõi dữ liệu y tế của bệnh nhân trong Dịch vụ Y tế quốc gia, bao gồm hệ thống rất nhiều bệnh viện tại Anh.
Mới đây, Google tiếp tục đàm phán với Genomic England, công ty do Bộ Y tế Anh thành lập giúp triển khai 100.000 Genomes Project, để hỏi xem liệu DeepMind có thể tham gia vào dự án của họ hay không.
Nếu câu trả lời từ phía Genomic England là có, DeepMind có thể giúp giảm thời gian và chi phí cho mỗi trình tự gen được sắp xếp. Nhưng việc một công ty tư nhân truy cập được vào các dữ liệu di truyền nhạy cảm cũng có mặt rủi ro của nó.
Đại diện bộ Y tế Anh cho biết mục đích họ cho phép DeepMind tham gia là để hỗ trợ chăm sóc y tế, nghiên cứu và giải mã trình tự gen trên quy mô lớn.
Chi phí để sắp xếp được trình tự gen trên quy mô dân số quốc gia là rất khủng khiếp. Năm 2003, bộ gen của một người đầu tiên được sắp xếp thành công mất tới 13 năm và 3 tỷ USD. Gần 2 thập kỷ sau đó, Veritas Genetics và Illumina, công ty chịu trách nhiệm sắp xếp trình tự gen cho dự án 100.000 Genomes Project, đã đưa giá thành xuống 1.000 USD/1 bộ gen, giảm tới 3 triệu lần.
Với sự tham gia của trí tuệ nhân tạo, DeepMind có thể tiếp tục giảm đáng kể chi phí cho dự án 100.000 Genomes Project. Nhất là trong bối cảnh hiện tại, chính phủ Anh đang muốn mở rộng dự án của họ vượt ra ngoài con số 100.000 người tham gia.
Ngoài ra, sự tham gia của trí tuệ nhân tạo cũng mang lại những lợi ích khác. Chẳng hạn, bằng các thuật toán liên kết dữ liệu sức khỏe có sẵn từ NHS và môi trường, DeepMind bây giờ có thể dự đoán tình trạng sức khỏe của người sở hữu bộ gen, ví dụ như nguy cơ mắc bệnh tim mạch.

Google đang khai thác dữ liệu di truyền, thứ định nghĩa lên người dùng của họ
Thế nhưng, những gì được công bố có thể mới chỉ là bề nổi. Năm 2016, DeepMind từng hợp tác với NHS để xây dựng một ứng dụng giúp nhân viên bệnh viện theo dõi bệnh nhân thận. Sau đó, người ta phát hiện thỏa thuận giữa hai phía đã vượt ra ngoài khuôn khổ dự án.
DeepMind đã thu thập hồ sơ của ít nhất 1,6 triệu bệnh nhân. Điều này rõ ràng đã vi phạm luật riêng tư của Vương Quốc Anh, mặc dù công ty khẳng định sẽ “không bao giờ dùng các dữ liệu này cho sản phẩm, dịch vụ của Google hoặc để thương mại hóa”.
Lần hợp tác với Genomic England này, đại diện Bộ Y tế Anh đã nhấn mạnh rằng dữ liệu có thể được ẩn danh. Nhưng nhiều người nghi ngờ rằng lời hứa này một lần nữa là không thật lòng. Dữ liệu được cung cấp cho DeepMind có thể vẫn bao gồm địa chỉ, độ tuổi và chỉ thay tên để “giả mạo” chứ không hoàn toàn là ẩn danh.
Trong kỷ nguyên số, dữ liệu được ví như dầu mỏ và dữ liệu gen là một giếng dầu chứa thông tin khổng lồ. Chúng ta phải tự hỏi rằng liệu có điều gì đang kiểm soát được hoạt động thu thập và mua bán dữ liệu hay không, đặc biệt là các dữ liệu di truyền.
Có thể, dữ liệu gen của rất nhiều người đã đang bị rò gỉ tại thời điểm này. Thông tin di truyền của một người có thể được thu thập dễ dàng, qua một mẫu tóc, máu hoặc nước bọt. Bởi vậy, sẽ cần những đạo luật rõ ràng cho lĩnh vực nghiên cứu và "thương mại" mới mẻ này.
Tại Mỹ, một dự luật đang được ủng hộ bởi Đảng Cộng hòa cho phép các công ty tư nhân có thể yêu cầu nhân viên xét nghiệm gen trước khi làm việc. Nếu từ chối tham gia, người lao động sẽ phải đóng bảo hiểm cao hơn.
Ở mặt còn lại, chưa có những chính sách cụ thể để minh bạch hóa và kiểm soát hoạt động thu thập và sử dụng dữ liệu di truyền của chính phủ và các công ty tư nhân. Rõ ràng, đó là những điều cần thiết để tạo môi trường cân bằng cho sự phát triển của các công nghệ di truyền trong tương lai.
Tham khảo Businessinsider
NỔI BẬT TRANG CHỦ

Chuyên gia MIT chia sẻ bí kíp tạo prompt để tận dụng sức mạnh của chatbot AI
Chatbot AI ngày nay là những phần mềm có thể được "lập trình" bằng ngôn ngữ tự nhiên.

Nhiều hình ảnh kỳ quặc xuất hiện trong một phim tài liệu, người dùng phẫn nộ vì nghi ngờ Netflix dùng AI tạo ra hình ảnh mà không thông báo
