Trí tuệ nhân tạo có một lỗ hổng bảo mật "chết người", các ông lớn như Google hay Amazon vẫn đang cố gắng tìm cách khắc phục
"Tất cả những hệ thống này đều có điểm yếu", Battista Biggio, trợ lý giáo sư tại Đại học Cagliari với 10 năm kinh nghiệm nghiên cứu AI nói.
- Bằng cách kết hợp machine learning và AR, ứng dụng miễn phí này có thể biến bạn thành một họa sĩ tài năng
- Cận cảnh VGA NVIDIA Titan V: Card đồ họa siêu khủng dùng cho Machine Learning, giá 129 triệu đồng.
- Chán nản vì chờ đợi tác giả, anh chàng tạo ra hệ thống sử dụng machine learning để viết tiếp tựa sách "Game of Thrones"
- Muốn lương 35 triệu/tháng tại Việt Nam - Hãy học Machine Learning, Big Data
- Rạng sáng thứ Sáu tới, NASA sẽ công bố phát hiện thiên văn mới, có được nhờ áp dụng machine learning
Mọi công ty công nghệ đang đều chạy theo xu hướng AI, họ gắn mọi sản phẩm của mình với trí tuệ nhân tạo với sức mạnh của những phần mềm machine learning. Nhưng chúng có một điểm yếu "chết người": chỉ cần thực hiện chút thay đổi trên một tấm ảnh, một bài viết hay một đoạn ghi âm, hệ thống đã có thể bị đánh lừa, nhận dạng chúng thành những thứ hoàn toàn khác.
Đây sẽ trở thành vấn đề lớn, nhất là khi mọi sản phẩm tương lai đều chạy theo xu hướng AI. BỊ ảnh hưởng nhất có lẽ là machine vision – hệ thống nhìn bằng máy, thường được áp dụng vào xe tự lái. Các nhà khoa học biết tới lỗ hổng này, đã có những cố gắng khắc phục nó nhưng chặng đường này vẫn còn rất gian nan.
Ví dụ cụ thể: tháng Giêng vừa rồi, một hội nghị về machine learning hàng đầu tuyên bố rằng họ đã chọn ra 11 báo cáo khoa học mới để công bố vào tháng Tư này, nhằm đưa ra giải pháp chống lại những đợt tấn công như vậy. Chỉ ba ngày sau tuyên bố ấy, cậu sinh viên tốt nghiệp MIT, Anish Athalye, đăng tải nghiên cứu của mình lên GitHub, cho thấy cậu đã bẻ khóa được 7 trong số 11 báo cáo khoa học trên, "nạn nhân" bao gồm cả những ông lớn như Google, Amazon và Standford.
"Một kẻ đủ khôn khéo có mục đích tấn công chắc chắn sẽ tìm được cách vượt qua những phương thức phòng vệ này", Anthalye nói. Dự án này được cậu, Nocholas Carlini và David Wagner, một là sinh viên tốt nghiệp một là giáo sư tại Đại học Berkeley, Mỹ.
Các nhà nghiên cứu AI người đồng tình người phản đối tuyên bố của bộ ba trên, nhưng có một thông điệp rõ ràng, rằng: ta chưa có biện pháp bảo vệ mạng lưới deep neural hiệu quả để yên tâm phát triển những phần mềm trí tuệ nhân tạo.

"Tất cả những hệ thống này đều có điểm yếu", Battista Biggio, trợ lý giáo sư tại Đại học Cagliari, Ý – người đã nghiên cứu bảo mật machine learning gần một thập kỷ nay nhưng không góp mặt trong nghiên cứu bẻ khóa AI trên, nói. "Cộng đồng nghiên cứu machine learning đang thiếu những cách thức phương pháp luận để đánh giá tính bảo mật".
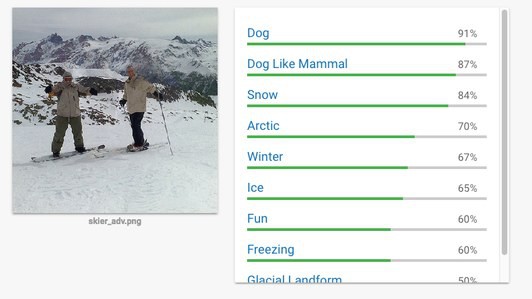
Trong hình ảnh dưới mà Athalye tạo ra, con người chúng ta có thể nhìn rõ là có hai người đang trượt tuyết. Tuy nhiên, khi hỏi Cloud Vision của Google, thì nó lại bảo đây là một con chó. Đây không phải ví dụ duy nhất, các thử nghiệm khác còn có thể biến biển dừng xe thành vô hình, thay đổi một đoạn ghi âm để máy nghe nhầm dù đối với tai chúng ta, nó vẫn là một câu bình thường.
Nhưng cho tới giờ, những thử nghiệm trên mới được thực hiện trong phòng thí nghiệm. Nhưng đó không phải lý do để ta xem nhẹ nó. Hệ thống nhìn đường của xe tự lái, trợ lý ảo có khả năng thực hiện thanh toán bằng giọng nói, các hệ thống machine learning lọc nội dung mạng đều cần phải đáng tin. Còn những thử nghiệm trên đều cho thấy những nguy hiểm tiềm tàng của việc hack hệ thống trí tuệ nhân tạo.

Ba công ty lớn đều không có tiếng nói rõ ràng trước những lỗ hổng này: Yang Song, tác giả của bài nghiên cứu của Standford từ chối bình luận; giáo sư Zachary Lipton từ Đại học Carnegie Mellon, người đã hỗ trợ Amazon nghiên cứu nói rằng ông chưa xem kỹ bản nghiên cứu lỗ hổng trên, nhưng nhiều khả năng là nó đã nói đúng; Google từ chối bình luận, nhưng phát ngôn viên của Google có nói rằng họ đang cập nhật hệ thống hòng chống lại những vụ tấn công tương tự có thể xảy ra trong tương lai.
Để có thể bảo vệ hiệu quả được các hệ thống machine learning này, các nhà nghiên cứu cần phải nghĩ khác đi. Athalye và Biggio nói rằng nên áp dụng thêm những phương thức thử nghiệm từ nghiên cứu bảo mật. "Bạn phải luôn nghi ngờ rằng có một cái gì đó tồi tệ có thể sẽ diễn ra". Những nhà nghiên cứu machine learning vẫn còn đặt nhiều niềm tin vào nó quá.
Tuy nhiên, hai khía cạnh bảo mật khác nhau cũng có những lợi thế và khó khăn riêng. Ví dụ, hệ thống phát hiện malware có thể được cải tiến để mạnh mẽ hơn một cách dễ dàng, nhưng bảo vệ được hệ thống quan sát bằng máy lại không dễ dàng thế. Thế giới tự nhiên quá đa dạng, một cái ảnh có thể có hàng tỷ pixel, phân tích hết để tìm ra lỗi quá khó khăn.
Để khắc phục được điểm yếu này, ta có thể phải định nghĩa lại cả machine learning. Một nhà nghiên cứu cho rằng vấn đề chính nằm ở việc mạng lưới deep neural khác với não bộ con người.
Mà con người cũng đâu có miễn nhiễm với những hình ảnh bị biến đổi, ta vẫn bị đánh lừa dễ dàng. Tuy nhiên ta có khả năng khác: khi nhìn vào một tấm ảnh, ngoài việc nhìn các pixel tạo nên hình ảnh gì, ta còn phân tích được mối quan hệ giữa các vật thể có trong ảnh, ví dụ như cách ta nhận dạng khuôn mặt chẳng hạn.
Có một nhà nghiên cứu machine learning tại Google đang cố cho phần mềm họ phát triển có được khả năng ấy. Phần mềm này có thể nhận dạng được thứ gì đó chỉ sau vài ảnh chứ không còn phải xem vài ngàn ảnh nữa. Một hệ thống có được tầm nhìn giống con người hơn sẽ hiệu quả hơn, hiển nhiên là như vậy.
Các nhà nghiên cứu machine learning hiện đang bắt tay với các nhà khoa học thần kinh, các nhà sinh vật học nhằm lợi dụng những khả năng sẵn có trong tự nhiên để áp dụng, cải thiện trí tuệ nhân tạo của tương lai.
NỔI BẬT TRANG CHỦ


